🧠 What is AI Speaker Identification?
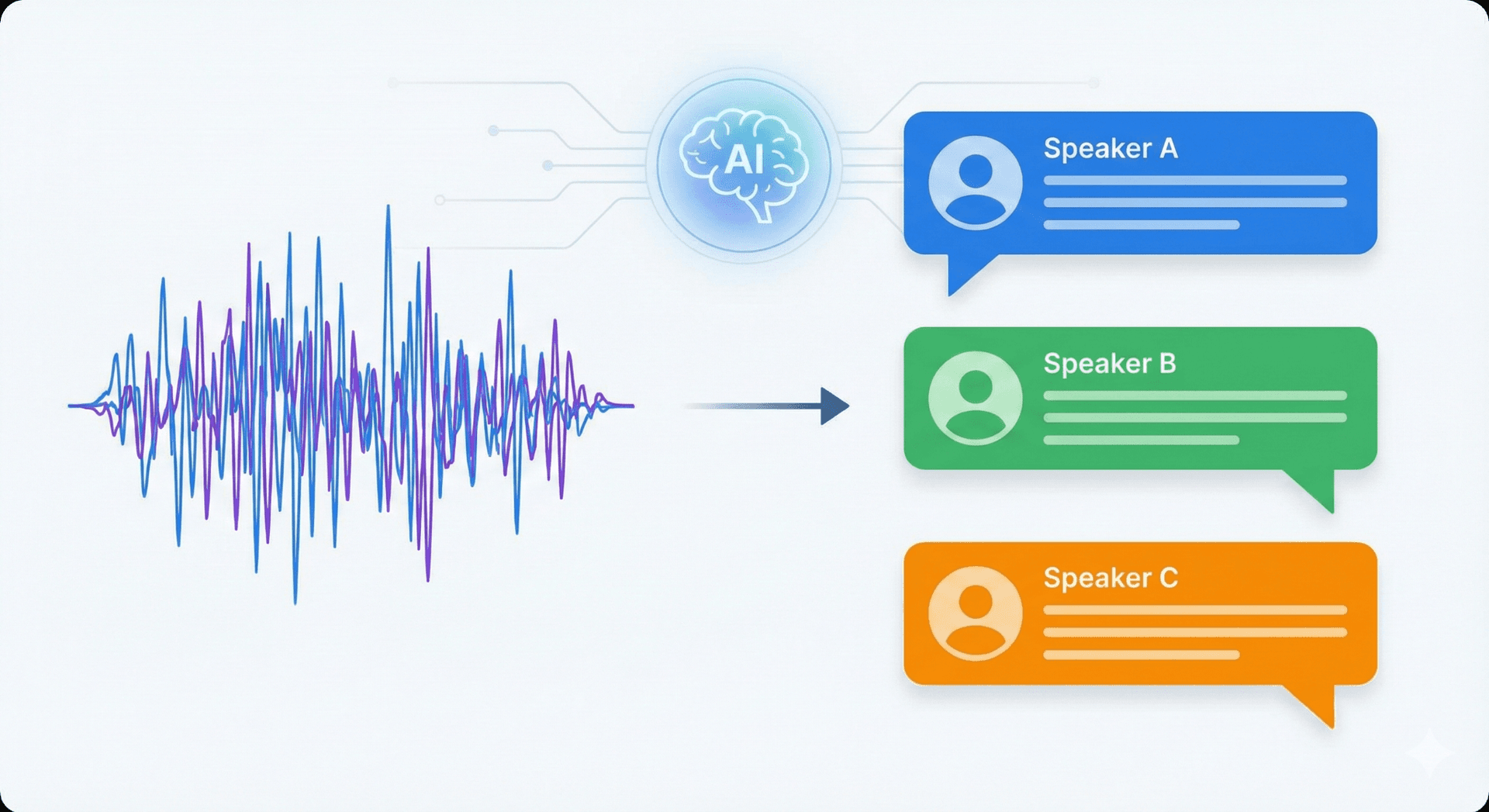
Speaker identification is the process of figuring out who is speaking in an audio recording. AI meeting tools that turn recordings into structured transcripts and short summaries need this feature because it lets systems link statements to the right person and preserve the conversation's context.
Technology Overview
- • Machine learning pattern matching
- • Acoustic feature extraction
- • Voice trait analysis (pitch, timbre)
- • Deep neural network processing
- • Speaker diarization & recognition
Key Applications
- • Tag speakers in transcripts
- • Create speaker-specific summaries
- • Enable speaker-based search
- • Track individual contributions
- • Generate action item assignments
🏆 Best AI Tools for Speaker Identification
| Tool | Rating | Key Features | Accuracy |
|---|---|---|---|
| Sembly | Excellent | ✓ Voice fingerprinting ✓ Real-time ID ✓ Speaker analytics ✓ Custom profiles | 98% |
| Fireflies | Excellent | ✓ Talk time analysis ✓ Sentiment tracking ✓ Interruption insights | 95% |
| Gong | Excellent | ✓ Customer vs rep tracking ✓ Talk ratio ✓ Objection detection | 96% |
| Otter.ai | Very Good | ✓ Easy labeling ✓ Voice training ✓ Quick corrections ✓ Highlights | 90% |
These tools integrate speaker identification into their core workflows, offering features like real-time diarization, speaker-specific analytics, and custom voice profiles. Whether you're managing a large enterprise meeting or a small team huddle, choosing the right tool can dramatically improve the quality and usability of your meeting summaries.
⚠️ Challenges and Considerations
Real-World Audio Challenges
Audio from the real world is messy. Accents, overlapping speech, background noise, and other similar vocal traits can make things less accurate. Segmentation is more complex when the recordings are short and of poor quality, and supervised training is limited by privacy or a lack of labeled data.
✅ What Helps Accuracy
- • High-quality audio - Good microphones, quiet environments
- • Distinct voices - Different genders, accents, speaking styles
- • Minimal overlap - Clear turn-taking in conversations
- • Consistent speakers - Same participants throughout
- • Longer recordings - More voice data for pattern analysis
- • Diverse training datasets - Better model robustness
❌ What Hurts Accuracy
- • Poor audio quality - Background noise, echo, distortion
- • Similar vocal traits - Same gender, age, speaking patterns
- • Frequent interruptions - Multiple simultaneous speakers
- • Short speaking segments - Insufficient voice data per speaker
- • Too many speakers - 10+ participants create complexity
- • Privacy constraints - Limited labeled training data
💡 Best Practices for Teams
To fix these problems, teams should focus on getting high-quality audio, use a variety of training datasets, and use noise-robust preprocessing. Transparent model evaluation and human review loops also help keep trust and accuracy.
Speaker Analytics & Insights
Talk Time Analysis
😊 Sentiment by Speaker
🔄 Interaction Patterns
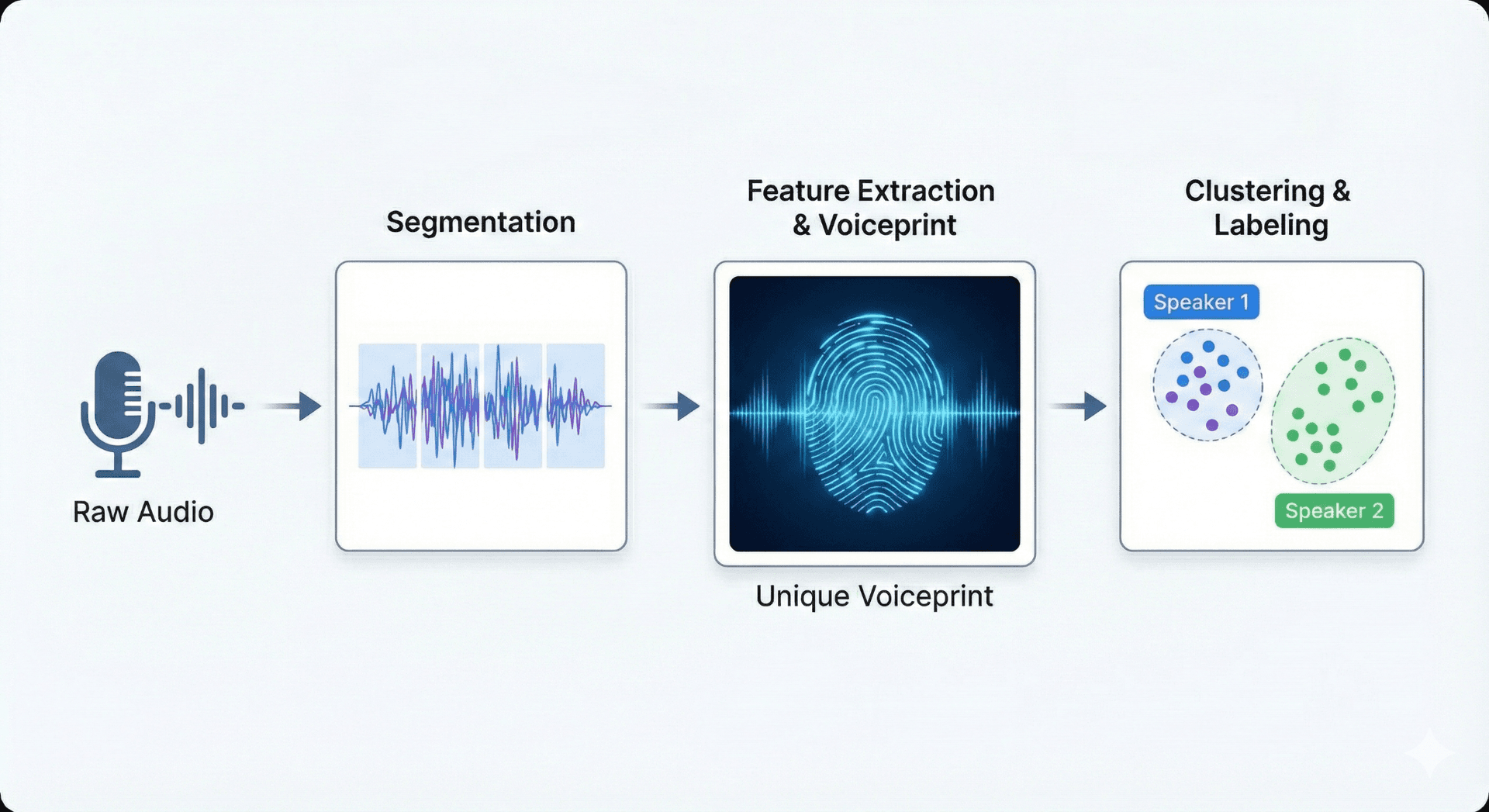
🔬 Speaker Identification Technology Overview
Speaker identification uses machine learning, pattern matching, and the extraction of acoustic features. Systems first convert audio into features (pitch, timbre, spectral patterns) that capture both physiological and behavioral voice traits. These features feed models, often deep neural networks or probabilistic classifiers, that learn to separate and label speakers across a recording.
Speaker Diarization
Segmenting audio by speaker turns - determining when each person starts and stops speaking.
- • Voice activity detection
- • Speaker change point detection
- • Audio segmentation by speaker
- • Timeline creation
Speaker Recognition
Matching voice segments to known identities and assigning speaker labels.
- • Voice fingerprint matching
- • Speaker profile creation
- • Identity verification
- • Label assignment
🚀 Future of Speaker Identification
Expect speaker ID to work better with other AI features, such as context-aware summarization that accounts for speakers' roles, emotion-aware tagging, and real-time captions that identify who is speaking during live calls.
Context-Aware AI
Summaries that understand speaker roles and relationships
Emotion Detection
Real-time sentiment analysis tied to specific speakers
Better Diversity
Improved accuracy across accents and speaking styles
Better self-supervised learning and bigger, more varied voice datasets will make it easier to understand accents and different settings. These changes, along with privacy-preserving techniques, will make speaker-aware meeting tools both more useful and more respectful of user data.
🎯 Conclusion
Speaker identification turns unorganized audio into useful information that can be traced back to the person who said it. This makes meetings more productive and helps people follow through on their commitments. AI summarization tools can deliver clearer transcripts, speaker-specific summaries, and searchable records by leveraging robust audio processing, machine learning, and careful data handling.
🚀 Ready for Action?
Check out the speaker-aware features to see how they can help you run your meetings more smoothly.