🧠 AI स्पीकर आइडेंटिफिकेशन क्या है?
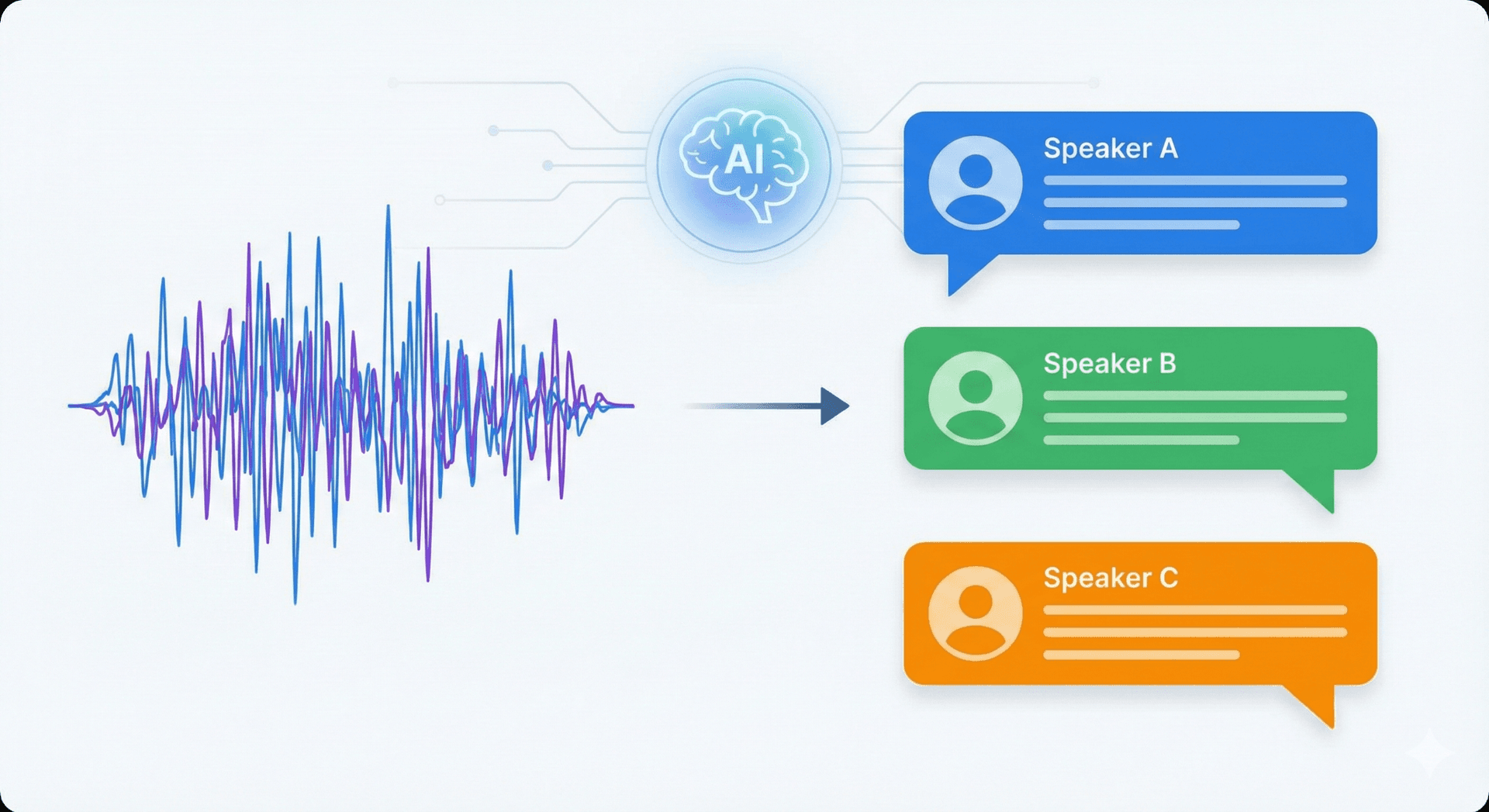
वक्ता पहचान वह प्रक्रिया है जिसमें यह पता लगाया जाता है कि किसी ऑडियो रिकॉर्डिंग में कौन बोल रहा है। AI मीटिंग टूल्स जो रिकॉर्डिंग को संरचित प्रतिलिपियों और छोटे सारांशों में बदलते हैं, उन्हें इस सुविधा की ज़रूरत होती है क्योंकि यह सिस्टमों को बयानों को सही व्यक्ति से जोड़ने और बातचीत के संदर्भ को संरक्षित रखने की अनुमति देती है।
प्रौद्योगिकी का अवलोकन
- • मशीन लर्निंग पैटर्न मिलान
- • ध्वनिक फीचर निष्कर्षण
- • वॉयस ट्रेट विश्लेषण (पिच, टिम्बर)
- • गहन न्यूरल नेटवर्क प्रसंस्करण
- • वक्ता डायरीज़ेशन और पहचान
मुख्य अनुप्रयोग
- • ट्रांसक्रिप्ट में वक्ताओं को टैग करें
- • वक्ता-विशिष्ट सारांश बनाएं
- • स्पीकर-आधारित खोज सक्षम करें
- • व्यक्तिगत योगदान को ट्रैक करें
- • क्रिया मद असाइनमेंट उत्पन्न करें
🏆 स्पीकर पहचान के लिए बेहतरीन AI टूल्स
| उपकरण | रेटिंग | मुख्य विशेषताएँ | सटीकता |
|---|---|---|---|
| Sembly | उत्कृष्ट | ✓ वॉइस फिंगरप्रिंटिंग ✓ रियल-टाइम आईडी ✓ वक्ता विश्लेषण ✓ कस्टम प्रोफाइल्स | 98% |
| Fireflies | उत्कृष्ट | ✓ बात करने के समय का विश्लेषण ✓ भावनात्मक ट्रैकिंग ✓ व्यवधान संबंधी जानकारियाँ | 95% |
| गोंग | उत्कृष्ट | ✓ ग्राहक बनाम प्रतिनिधि ट्रैकिंग ✓ बात करने का अनुपात ✓ आपत्ति पहचान | 96% |
| Otter.ai | बहुत अच्छा | ✓ आसान लेबलिंग ✓ वॉइस प्रशिक्षण ✓ त्वरित सुधार ✓ मुख्य बिंदु | 90% |
ये टूल्स अपने मुख्य वर्कफ़्लो में स्पीकर आइडेंटिफिकेशन को शामिल करते हैं, और रियल‑टाइम डायरीज़ेशन, स्पीकर‑विशिष्ट एनालिटिक्स, तथा कस्टम वॉइस प्रोफाइल जैसी सुविधाएँ प्रदान करते हैं। चाहे आप एक बड़ी एंटरप्राइज़ मीटिंग मैनेज कर रहे हों या छोटी टीम की हडल, सही टूल चुनना आपकी मीटिंग समरीज़ की गुणवत्ता और उपयोगिता को नाटकीय रूप से बेहतर बना सकता है।
⚠️ चुनौतियाँ और विचारणीय बिंदु
वास्तविक दुनिया की ऑडियो चुनौतियाँ
वास्तविक दुनिया का ऑडियो अस्त-व्यस्त होता है। उच्चारण, एक साथ बोलना, पृष्ठभूमि शोर, और अन्य समान स्वर संबंधी विशेषताएँ सटीकता को कम कर सकती हैं। जब रिकॉर्डिंग छोटी और कम गुणवत्ता वाली होती हैं, तो विभाजन (segmentation) अधिक जटिल हो जाता है, और गोपनीयता या लेबल किए गए डेटा की कमी के कारण सुपरवाइज्ड प्रशिक्षण सीमित हो जाता है।
✅ क्या सटीकता में मदद करता है
- • उच्च-गुणवत्ता वाली ऑडियो - अच्छे माइक्रोफ़ोन, शांत वातावरण
- • विशिष्ट आवाज़ें - अलग-अलग लिंग, उच्चारण, बोलने की शैली
- • न्यूनतम ओवरलैप - बातचीत में स्पष्ट बारी-बारी से बोलना
- • सुसंगत वक्ता - पूरे समय वही प्रतिभागी
- • लंबी रिकॉर्डिंग्स - पैटर्न विश्लेषण के लिए अधिक वॉइस डेटा
- • विविध प्रशिक्षण डेटासेट - बेहतर मॉडल मजबूती
❌ क्या सटीकता को नुकसान पहुँचाता है
- • खराब ऑडियो गुणवत्ता - पृष्ठभूमि शोर, इको, विकृति
- • समान वोकल विशेषताएँ - वही लिंग, उम्र, बोलने के पैटर्न
- • बार-बार रुकावटें - कई लोग एक साथ बोल रहे हैं
- • छोटे बोलने वाले खंड - प्रति वक्ता अपर्याप्त वॉइस डेटा
- • बहुत अधिक वक्ता - 10+ प्रतिभागी जटिलता पैदा करते हैं
- • गोपनीयता सीमाएँ - सीमित लेबलयुक्त प्रशिक्षण डेटा
💡 टीमों के लिए सर्वोत्तम प्रथाएँ
इन समस्याओं को ठीक करने के लिए, टीमों को उच्च-गुणवत्ता वाला ऑडियो प्राप्त करने पर ध्यान देना चाहिए, विभिन्न प्रकार के प्रशिक्षण डेटासेट का उपयोग करना चाहिए, और शोर-रोधी प्रीप्रोसेसिंग अपनानी चाहिए। पारदर्शी मॉडल मूल्यांकन और मानवीय समीक्षा लूप भी भरोसा और सटीकता बनाए रखने में मदद करते हैं।
स्पीकर एनालिटिक्स और इनसाइट्स
बातचीत समय विश्लेषण
😊 वक्ता के अनुसार भावनात्मक विश्लेषण
🔄 इंटरैक्शन पैटर्न्स
🔬 वक्ता पहचान तकनीक का अवलोकन
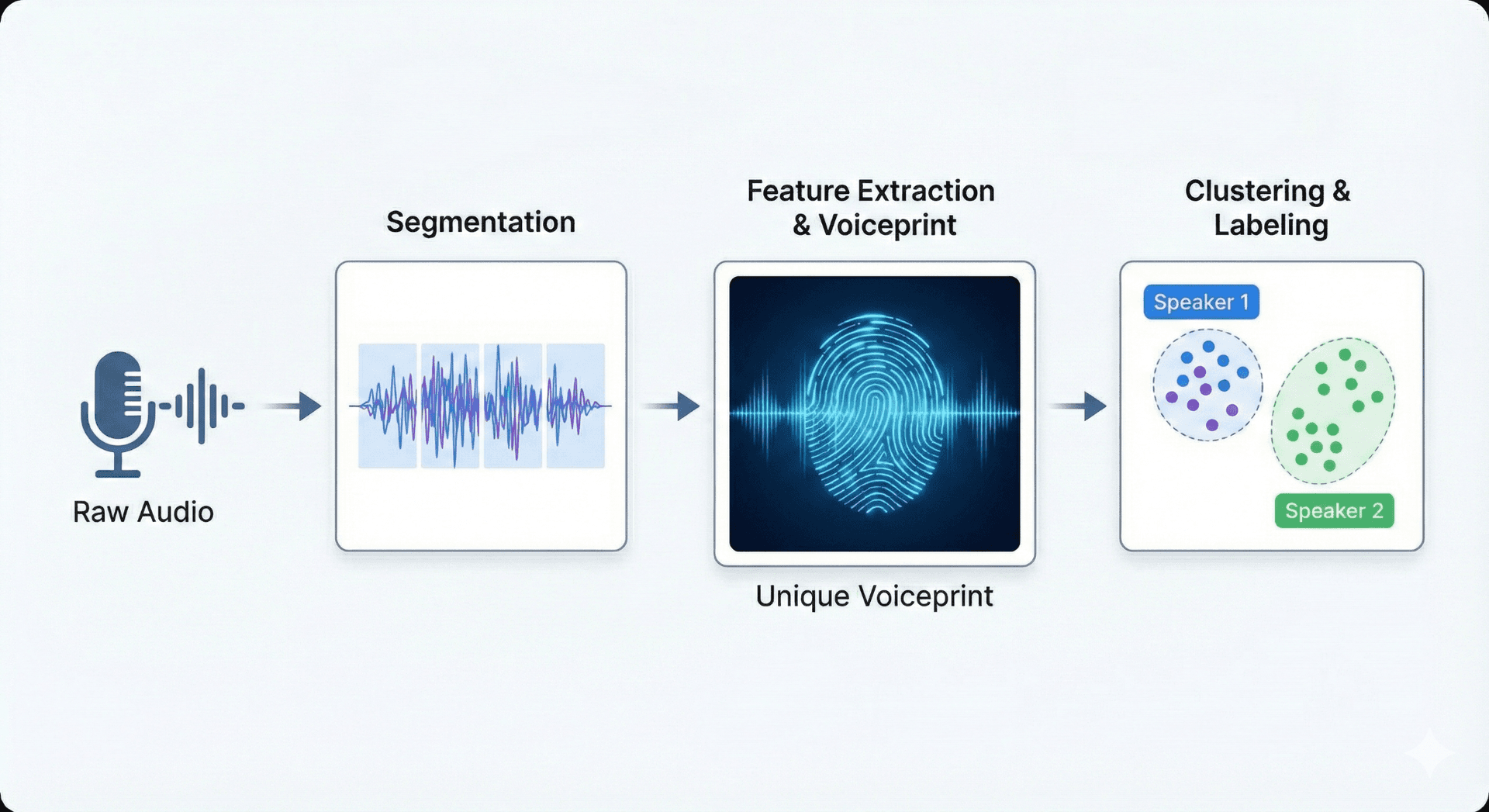
स्पीकर पहचान मशीन लर्निंग, पैटर्न मैचिंग, और ध्वनिक विशेषताओं के निष्कर्षण का उपयोग करती है। सिस्टम सबसे पहले ऑडियो को विशेषताओं (पिच, टिम्बर, स्पेक्ट्रल पैटर्न) में बदलते हैं जो शारीरिक और व्यवहारिक दोनों तरह के वॉइस गुणों को कैप्चर करती हैं। ये विशेषताएँ मॉडलों को फीड की जाती हैं, जो अक्सर डीप न्यूरल नेटवर्क या प्रायिकतामूलक क्लासिफायर होते हैं, जो किसी रिकॉर्डिंग में विभिन्न स्पीकर्स को अलग-अलग करना और लेबल करना सीखते हैं।
स्पीकर डायराइजेशन
स्पीकर टर्न के आधार पर ऑडियो को खंडों में बांटना - यह निर्धारित करना कि हर व्यक्ति कब बोलना शुरू करता है और कब बोलना बंद करता है।
- • वॉयस एक्टिविटी डिटेक्शन
- • वक्ता परिवर्तन बिंदु पहचान
- • वक्ता के अनुसार ऑडियो विभाजन
- • समयरेखा निर्माण
वक्ता पहचान
ज्ञात पहचानों से वॉइस सेगमेंट्स का मिलान करना और वक्ताओं को लेबल सौंपना।
- • वॉइस फिंगरप्रिंट मिलान
- • वक्ता प्रोफ़ाइल निर्माण
- • पहचान सत्यापन
- • लेबल असाइनमेंट
🚀 वक्ता पहचान का भविष्य
अन्य AI फीचर्स के साथ स्पीकर आईडी के बेहतर काम करने की उम्मीद करें, जैसे कि संदर्भ-उन्मुख सारांश जो वक्ताओं की भूमिकाओं को ध्यान में रखता है, भावनाओं के प्रति संवेदनशील टैगिंग, और रीयल-टाइम कैप्शन जो लाइव कॉल के दौरान यह पहचानते हैं कि कौन बोल रहा है।
संदर्भ-सचेत AI
सारांश जो वक्ताओं की भूमिकाओं और संबंधों को समझते हैं
भावना पहचान
विशिष्ट वक्ताओं से जुड़ा रियल-टाइम भाव विश्लेषण
बेहतर विविधता
उच्चारणों और बोलने की शैलियों में बेहतर सटीकता
बेहतर स्व-पर्यवेक्षित लर्निंग और बड़ी, अधिक विविध वॉयस डेटासेट्स उच्चारणों और अलग-अलग सेटिंग्स को समझना आसान बना देंगी। ये बदलाव, गोपनीयता-संरक्षण तकनीकों के साथ मिलकर, स्पीकर-अवेयर मीटिंग टूल्स को उपयोगकर्ता डेटा के प्रति अधिक सम्मानजनक और साथ ही अधिक उपयोगी बना देंगे।
🎯 निष्कर्ष
स्पीकर पहचान अव्यवस्थित ऑडियो को उपयोगी जानकारी में बदल देती है, जिसे उस व्यक्ति तक वापस ट्रेस किया जा सकता है जिसने वह बात कही थी। इससे मीटिंग्स अधिक उत्पादक बनती हैं और लोगों को अपनी प्रतिबद्धताओं को पूरा करने में मदद मिलती है। AI सारांशण टूल्स मजबूत ऑडियो प्रोसेसिंग, मशीन लर्निंग और सावधानीपूर्वक डेटा हैंडलिंग का उपयोग करके अधिक स्पष्ट ट्रांसक्रिप्ट्स, स्पीकर-विशिष्ट सारांश, और खोजने योग्य रिकॉर्ड प्रदान कर सकते हैं।
🚀 कार्रवाई के लिए तैयार?
स्पीकर-अवेयर फीचर्स को देखें ताकि आप जान सकें कि वे आपकी मीटिंग्स को और अधिक सुचारू रूप से चलाने में कैसे मदद कर सकते हैं।