🧠 Was ist KI-Lautsprechererkennung?
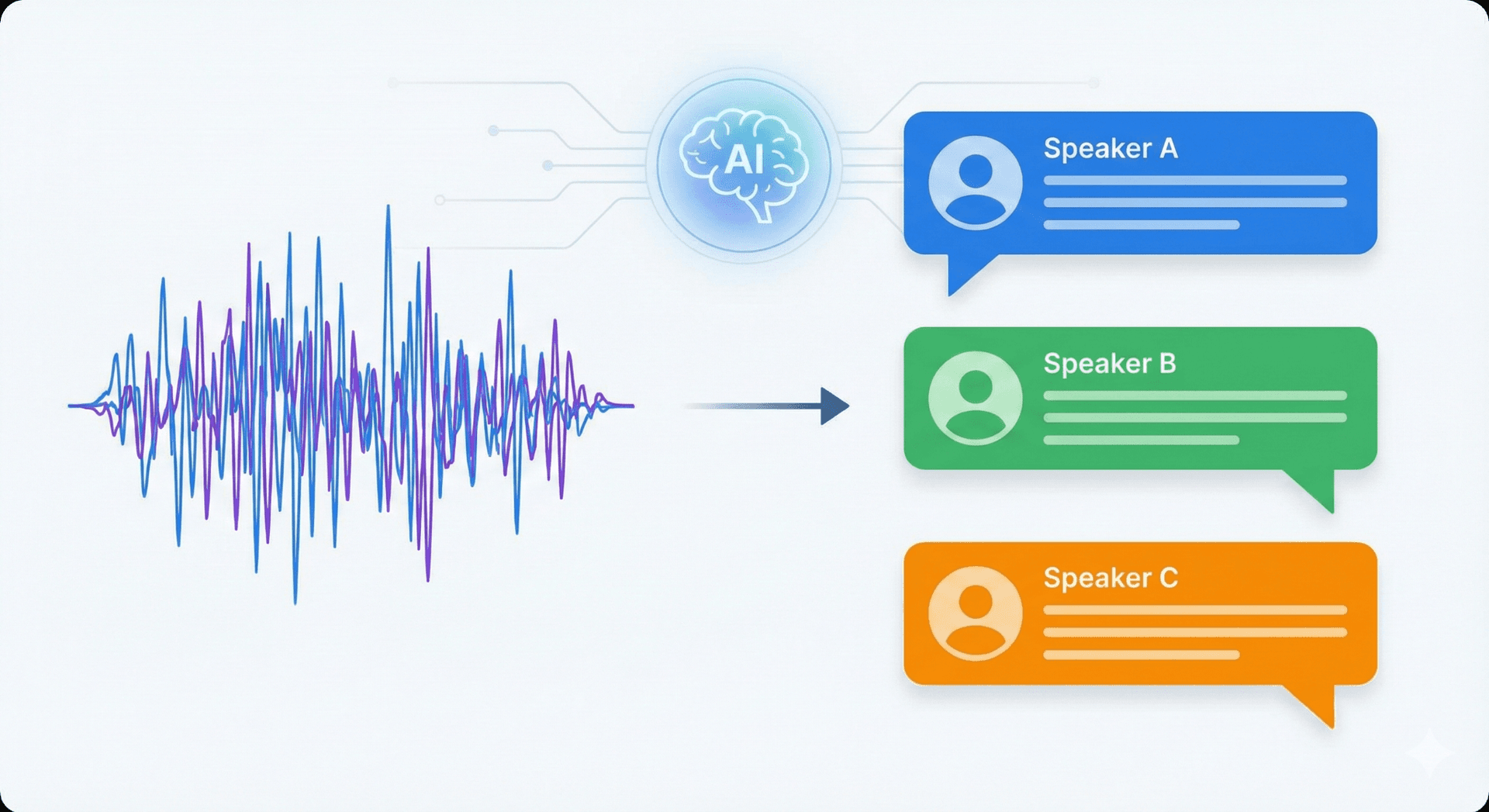
Die Sprecheridentifikation ist der Prozess, mit dem festgestellt wird, wer in einer Audioaufnahme spricht. KI-Meeting-Tools, die Aufnahmen in strukturierte Transkripte und kurze Zusammenfassungen umwandeln, benötigen diese Funktion, weil sie es den Systemen ermöglicht, Aussagen der richtigen Person zuzuordnen und den Kontext des Gesprächs zu bewahren.
Technologieübersicht
- • Mustererkennung im maschinellen Lernen
- • Akustische Merkmalsextraktion
- • Stimmerkennungsanalyse (Tonhöhe, Klangfarbe)
- • Verarbeitung mittels tiefen neuronalen Netzwerken
- • Sprecherdiarisierung & -erkennung
Schlüsselanwendungen
- • Sprecher in Transkripten markieren
- • Erstelle sprecherspezifische Zusammenfassungen
- • Sprecherbasierte Suche aktivieren
- • Individuelle Beiträge nachverfolgen
- • Aktionspunkte zuweisen
🏆 Beste KI-Tools zur Sprechererkennung
| Werkzeug | Bewertung | Hauptfunktionen | Genauigkeit |
|---|---|---|---|
| Sembly | Ausgezeichnet | ✓ Stimmabdruck ✓ Echtzeit-ID ✓ Sprecheranalysen ✓ Benutzerdefinierte Profile | 98% |
| Fireflies | Ausgezeichnet | ✓ Gesprächszeitanalyse ✓ Sentiment-Tracking ✓ Unterbrechungs-Einblicke | 95% |
| Gong | Ausgezeichnet | ✓ Kunden- vs. Vertreter-Tracking ✓ Gesprächsanteil ✓ Einwandserkennung | 96% |
| Otter.ai | Sehr gut | ✓ Einfaches Labeling ✓ Stimmtraining ✓ Schnelle Korrekturen ✓ Highlights | 90% |
Diese Tools integrieren Sprechererkennung in ihre Kern-Workflows und bieten Funktionen wie Echtzeit-Diarisierung, sprecherspezifische Analysen und individuelle Stimmprofile. Ganz gleich, ob Sie ein großes Unternehmensmeeting oder eine kleine Teambesprechung leiten – die Wahl des richtigen Tools kann die Qualität und Nutzbarkeit Ihrer Meeting-Zusammenfassungen erheblich verbessern.
⚠️ Herausforderungen und Überlegungen
Audio-Herausforderungen in der realen Welt
Audio aus der realen Welt ist chaotisch. Akzente, sich überschneidende Sprache, Hintergrundgeräusche und andere ähnliche stimmliche Merkmale können die Genauigkeit verringern. Die Segmentierung ist komplexer, wenn die Aufnahmen kurz und von schlechter Qualität sind, und überwachtes Training ist durch Datenschutz oder einen Mangel an gelabelten Daten eingeschränkt.
✅ Was die Genauigkeit verbessert
- • Hochwertige Audioqualität – Gute Mikrofone, ruhige Umgebungen
- • Unterschiedliche Stimmen – Verschiedene Geschlechter, Akzente, Sprechweisen
- • Minimale Überschneidung - Klare Gesprächsführung mit abwechselnden Beiträgen
- • Konsistente Sprecher – Gleiche Teilnehmenden durchgehend
- • Längere Aufnahmen – Mehr Sprachdaten für Musteranalysen
- • Vielfältige Trainingsdatensätze – bessere Modellrobustheit
❌ Was die Genauigkeit beeinträchtigt
- • Schlechte Audioqualität – Hintergrundgeräusche, Echo, Verzerrung
- • Ähnliche stimmliche Merkmale – Gleiches Geschlecht, Alter, Sprechmuster
- • Häufige Unterbrechungen – Mehrere gleichzeitige Sprecher
- • Kurze Sprechsegmente – Unzureichende Sprachdaten pro Sprecher
- • Zu viele Sprecher – mehr als 10 Teilnehmende sorgen für Komplexität
- • Datenschutzbeschränkungen – Begrenzte gelabelte Trainingsdaten
💡 Best Practices für Teams
Um diese Probleme zu beheben, sollten Teams sich auf hochwertige Audioaufnahmen konzentrieren, eine Vielzahl von Trainingsdatensätzen verwenden und robuste Vorverarbeitung gegen Rauschen einsetzen. Transparente Modellevaluation und menschliche Kontrollschleifen tragen ebenfalls dazu bei, Vertrauen und Genauigkeit zu bewahren.
Analyse und Einblicke zu Sprecher:innen
Analyse der Sprechzeit
😊 Stimmung nach Sprecher
🔄 Interaktionsmuster
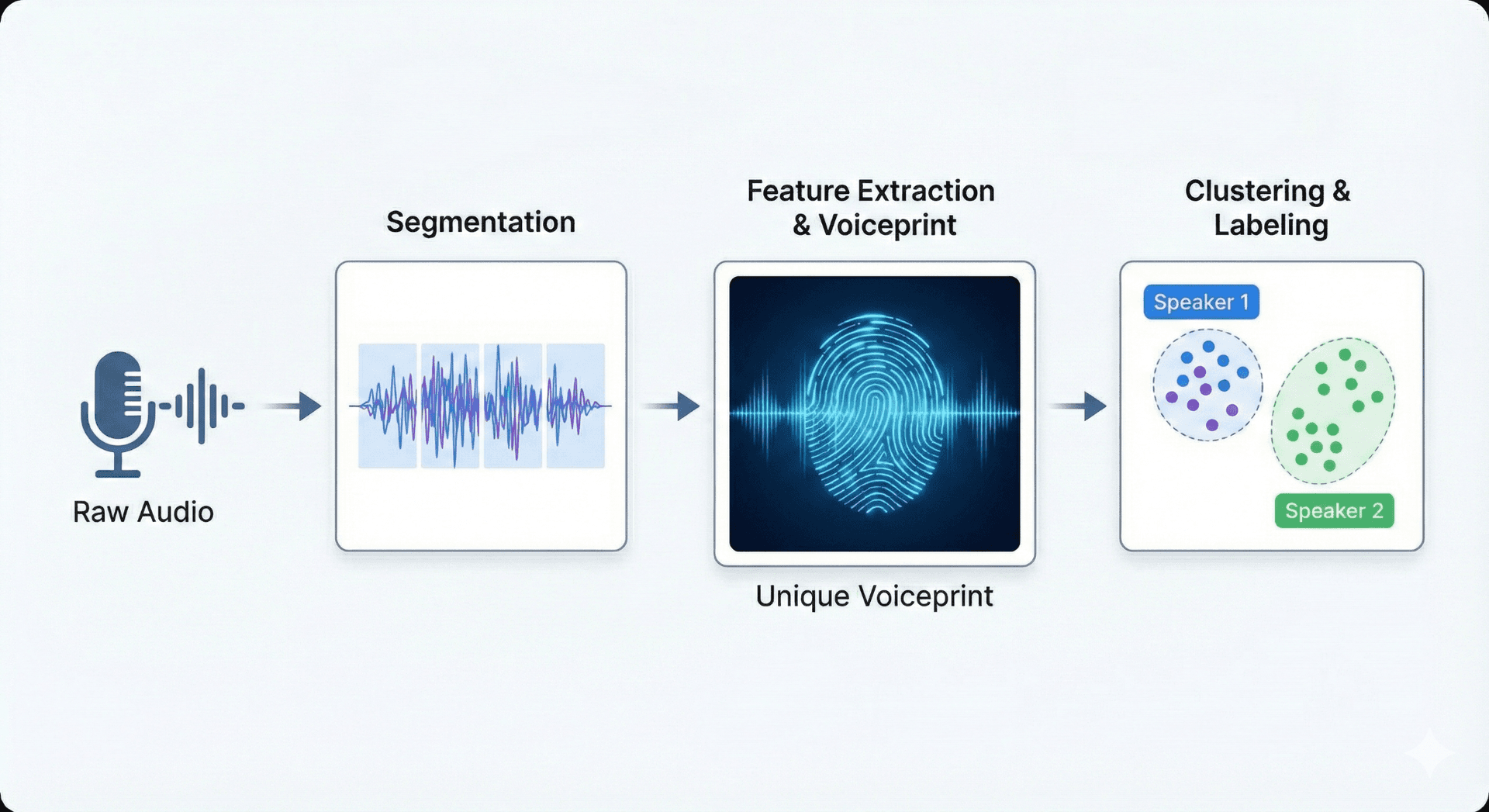
🔬 Überblick über Sprecheridentifikationstechnologie
Die Sprechererkennung verwendet maschinelles Lernen, Mustererkennung und die Extraktion akustischer Merkmale. Systeme wandeln Audio zunächst in Merkmale (Tonhöhe, Klangfarbe, spektrale Muster) um, die sowohl physiologische als auch Verhaltensmerkmale der Stimme erfassen. Diese Merkmale speisen Modelle, häufig tiefe neuronale Netze oder probabilistische Klassifikatoren, die lernen, Sprecher innerhalb einer Aufnahme zu unterscheiden und zu kennzeichnen.
Sprecher-Diarisierung
Segmentierung von Audio anhand von Sprecherwechseln – Bestimmung, wann jede Person beginnt und aufhört zu sprechen.
- • Spracherkennung für Sprachaktivität
- • Erkennung von Sprecherwechselpunkten
- • Audiosegmentierung nach Sprecher
- • Erstellung einer Zeitleiste
Spracherkennung
Abgleichen von Sprachsegmenten mit bekannten Identitäten und Zuweisen von Sprecherlabels.
- • Stimmabdruckabgleich
- • Erstellung von Sprecherprofilen
- • Identitätsüberprüfung
- • Labelzuweisung
🚀 Zukunft der Sprechererkennung
Erwarten Sie, dass die Sprechererkennung besser mit anderen KI-Funktionen zusammenarbeitet, z. B. kontextbezogenen Zusammenfassungen, die die Rollen der Sprecher berücksichtigen, emotionssensitiver Verschlagwortung und Echtzeit-Untertiteln, die während Live-Anrufen anzeigen, wer gerade spricht.
Kontextbewusste KI
Zusammenfassungen, die Sprecherrollen und Beziehungen verstehen
Emotionserkennung
Echtzeit-Stimmungsanalyse, die an bestimmte Sprecher gekoppelt ist
Bessere Vielfalt
Verbesserte Genauigkeit bei verschiedenen Akzenten und Sprechstilen
Bessere selbstüberwachte Lernverfahren und größere, vielfältigere Sprachdatensätze werden es erleichtern, Akzente und unterschiedliche Umgebungen zu verstehen. Diese Veränderungen, zusammen mit datenschutzfreundlichen Techniken, werden sprecherbewusste Meeting-Tools sowohl nützlicher als auch respektvoller im Umgang mit Nutzerdaten machen.
🎯 Fazit
Die Sprechererkennung verwandelt unorganisierte Audiodaten in nützliche Informationen, die der Person zugeordnet werden können, die sie geäußert hat. Das macht Meetings produktiver und hilft Menschen, ihre Zusagen einzuhalten. KI-Zusammenfassungstools können durch den Einsatz von leistungsstarker Audiobearbeitung, Machine Learning und sorgfältigem Umgang mit Daten klarere Transkripte, sprecherspezifische Zusammenfassungen und durchsuchbare Aufzeichnungen liefern.
🚀 Bereit für Action?
Entdecken Sie die sprecherbezogenen Funktionen, um zu sehen, wie sie Ihnen helfen können, Ihre Meetings reibungsloser durchzuführen.