🧠 AI話者識別とは何ですか?
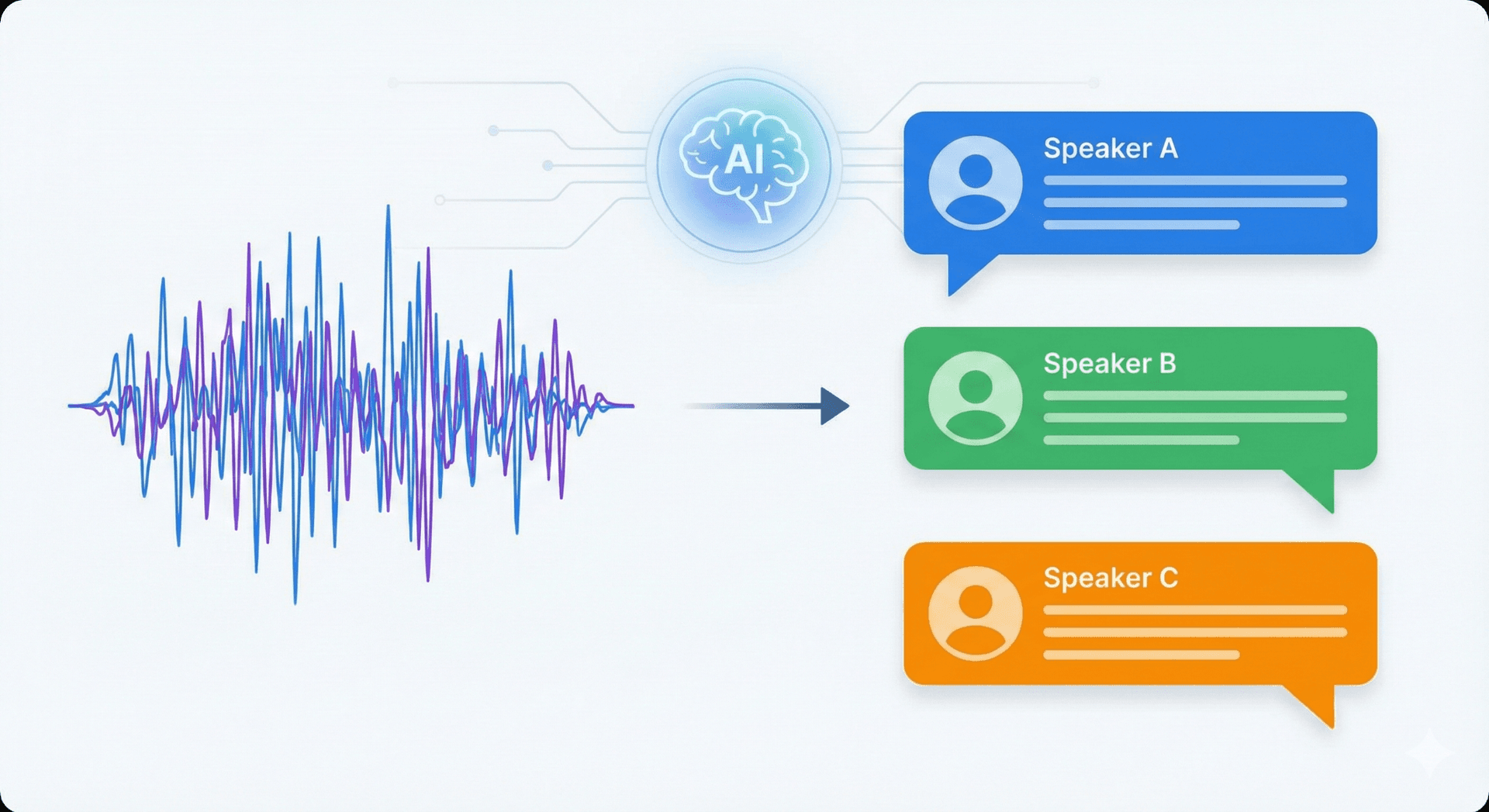
話者識別とは、音声録音の中で「誰が話しているか」を特定するプロセスです。録音を構造化された文字起こしや短い要約に変換するAIミーティングツールには、この機能が必要です。なぜなら、発言を正しい人物に結びつけ、会話の文脈を保つことができるからです。
テクノロジー概要
- ・機械学習によるパターンマッチング
- ・音響特徴抽出
- ・声の特徴分析(ピッチ、音色)
- ・ディープニューラルネットワーク処理
- • 話者分離と話者認識
主要なアプリケーション
- ・文字起こし内の話者にタグを付ける
- ・話者ごとの要約を作成
- ・話者別検索を有効にする
- ・個々の貢献度を追跡する
- ・アクションアイテムの担当者を割り当てる
🏆 話者識別に最適なAIツール
| ツール | 評価 | 主な機能 | 正確さ |
|---|---|---|---|
| Sembly | 素晴らしい | ✓ ボイスフィンガープリンティング ✓ リアルタイムID ✓ 話者分析 ✓ カスタムプロフィール | 98% |
| Fireflies | 素晴らしい | ✓ 通話時間の分析 ✓ センチメント追跡 ✓ 割り込みインサイト | 95% |
| ゴング | 素晴らしい | ✓ 顧客対担当者の追跡 ✓ 話した比率 ✓ 異議の検出 | 96% |
| Otter.ai | とても良い | ✓ 簡単なラベリング ✓ ボイストレーニング ✓ クイック修正 ✓ ハイライト | 90% |
これらのツールは話者識別をコアのワークフローに統合しており、リアルタイムのダイアライゼーション、話者ごとの分析、カスタムボイスプロファイルといった機能を提供しています。大規模なエンタープライズの会議を管理する場合でも、小規模なチームミーティングを運営する場合でも、適切なツールを選ぶことで、会議要約の品質と利便性を大幅に向上させることができます。
⚠️ 課題と考慮事項
実際の音声における課題
現実世界の音声は雑然としています。訛り、話者の重なり、背景雑音、その他類似した発話の特徴によって、精度が低下することがあります。録音が短く品質が悪い場合、セグメンテーションはさらに複雑になり、プライバシーの制約やラベル付きデータの不足により、教師あり学習にも限界があります。
✅ 正確さを高めるポイント
- ・高品質な音声 - 良いマイク、静かな環境
- ・はっきり区別できる声 - 異なる性別、アクセント、話し方
- ・重なりが最小限 ― 会話での明確な順番の取り方
- ・一貫した話者 ― 参加者が終始同じ
- ・より長い録音 - パターン分析のための音声データが増加
- ・多様な学習データセット - モデルの堅牢性向上
❌ 精度を損なう要因
- • 音声品質が悪い - 背景雑音、エコー、歪み
- ・類似した声の特徴 - 同じ性別、年齢、話し方のパターン
- ・頻繁な割り込み - 複数人が同時に話す
- ・短い発話セグメント - 話者ごとの音声データが不十分
- ・話者が多すぎる - 10人以上の参加者がいると複雑になる
- ・プライバシー上の制約 ― ラベル付き学習データの不足
💡 チームのベストプラクティス
これらの問題を解決するために、チームは高品質な音声の取得に注力し、さまざまな訓練用データセットを使用し、ノイズに強い前処理を行うべきです。透明性のあるモデル評価と人によるレビューループも、信頼性と精度を維持するうえで役立ちます。
話者分析とインサイト
通話時間分析
😊 話者別の感情分析
🔄 インタラクションパターン
🔬 話者識別技術の概要
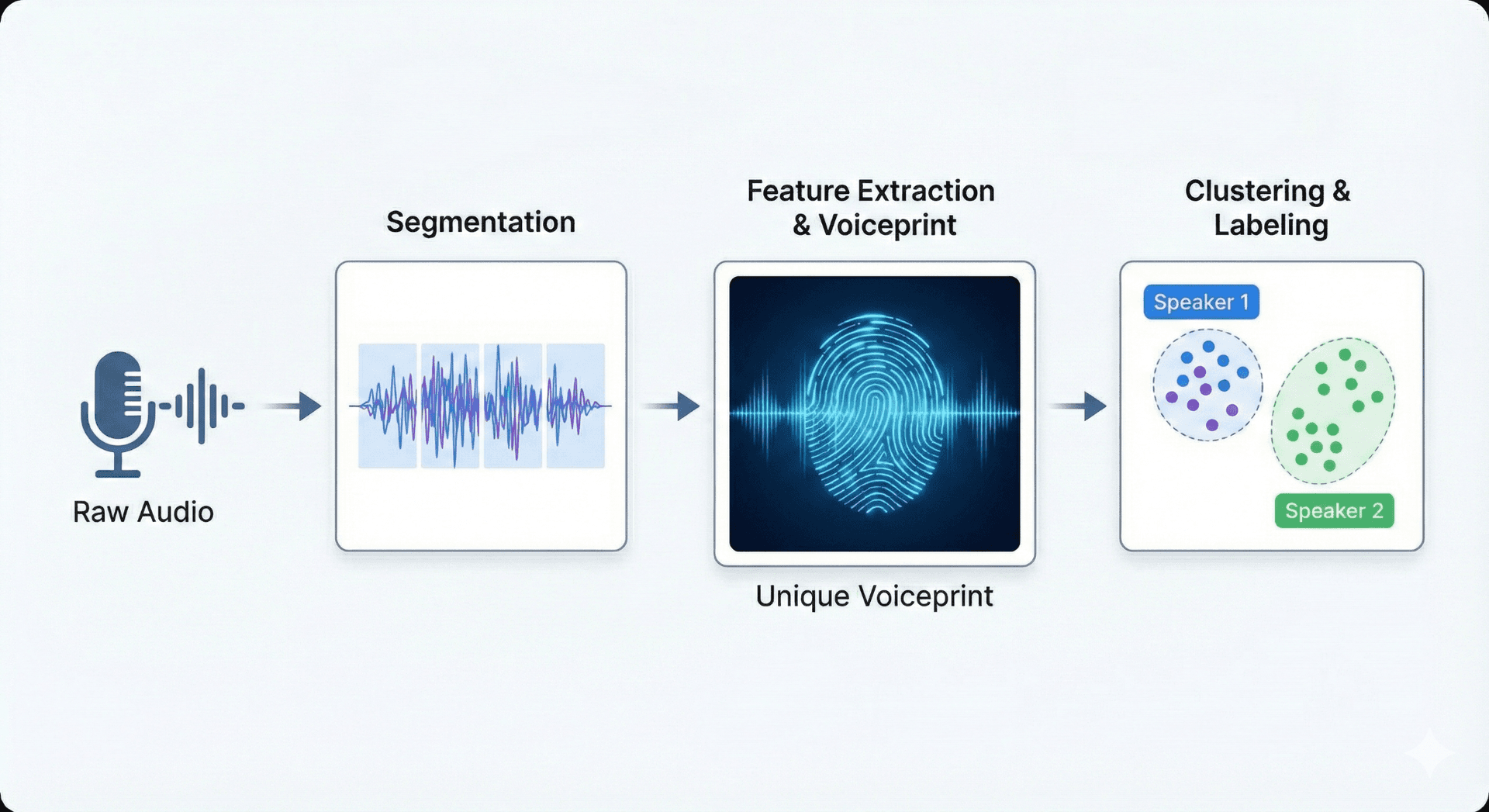
話者識別では、機械学習、パターンマッチング、そして音響特徴の抽出が利用されます。システムはまず、音声を生理的および行動的な声の特徴を捉える特徴量(ピッチ、音色、スペクトルパターンなど)に変換します。これらの特徴量がモデル、しばしば深層ニューラルネットワークや確率的分類器に入力され、録音全体にわたって話者を分離し、ラベル付けする方法を学習します。
話者ダイアライゼーション
話者の発話交代ごとに音声を区切り、各人がいつ話し始めていつ話し終えるかを判定すること。
- ・音声活動検出
- ・話者交代点検出
- ・話者ごとの音声セグメンテーション
- ・タイムライン作成
話者認識
既知の話者情報と音声セグメントを照合し、話者ラベルを割り当てること。
- ・声紋照合
- • スピーカープロファイルの作成
- • 本人確認
- ・ラベルの割り当て
🚀 話者識別の未来
スピーカーIDは、発言者の役割を考慮したコンテキスト対応の要約や、感情認識タグ付け、ライブ通話中に誰が話しているかを特定するリアルタイム字幕など、他のAI機能と組み合わせることで、さらにうまく機能することが期待されています。
コンテキスト対応AI
話し手の役割や関係性を理解した要約
感情検出
特定の話者に紐づいたリアルタイム感情分析
より良い多様性
さまざまなアクセントや話し方にわたる精度の向上
より優れた自己教師あり学習と、より大規模で多様な音声データセットによって、アクセントやさまざまな環境を理解しやすくなります。これらの変化は、プライバシーを保護する技術とあいまって、話者を認識できるミーティングツールを、ユーザーデータに対してより有用かつより尊重したものにしていくでしょう。
🎯 結論
話者識別は、まとまりのない音声を、誰が話したのかをさかのぼることができる有用な情報に変換します。これにより、会議はより生産的になり、人々が自分の約束をきちんと果たすことに役立ちます。AI 要約ツールは、強力な音声処理、機械学習、そして慎重なデータ処理を活用することで、より明瞭な文字起こし、話者ごとの要約、検索可能な記録を提供できます。