🧠 Che cos'è l'Identificazione del Parlante tramite IA?
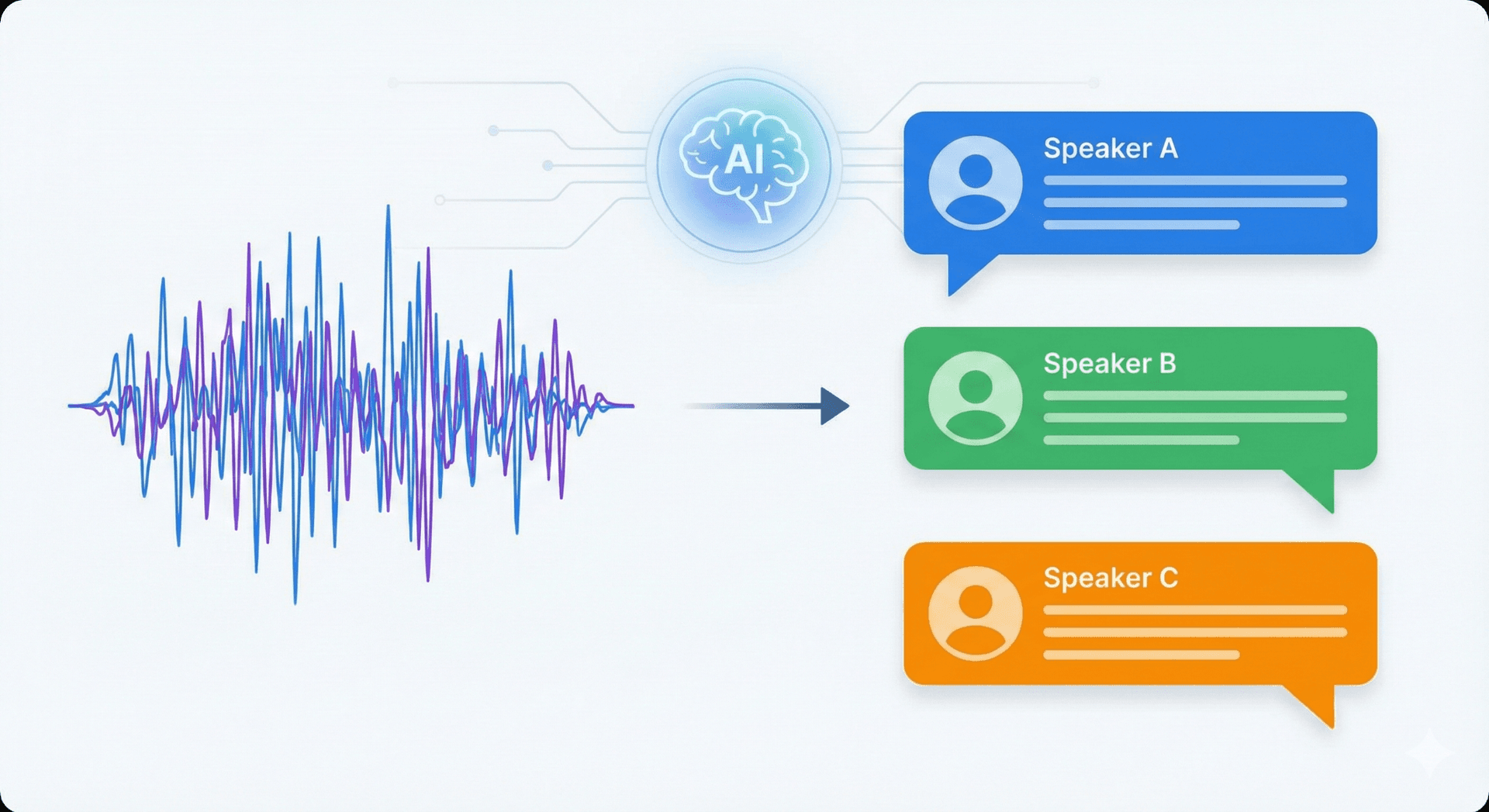
L'identificazione del parlante è il processo di individuare chi sta parlando in una registrazione audio. Gli strumenti di riunione basati sull'IA che trasformano le registrazioni in trascrizioni strutturate e brevi riepiloghi hanno bisogno di questa funzionalità perché consente ai sistemi di collegare le affermazioni alla persona giusta e preservare il contesto della conversazione.
Panoramica Tecnologica
- • Riconoscimento di schemi tramite machine learning
- • Estrazione delle caratteristiche acustiche
- • Analisi delle caratteristiche vocali (tono, timbro)
- • Elaborazione tramite reti neurali profonde
- • Diarizzazione e riconoscimento dei parlanti
Applicazioni chiave
- • Tagga i relatori nelle trascrizioni
- • Crea riepiloghi specifici per ogni relatore
- • Abilita la ricerca per relatore
- • Tieni traccia dei contributi individuali
- • Genera assegnazioni di attività azionabili
🏆 Migliori strumenti di IA per l’identificazione dei parlanti
| Strumento | Valutazione | Caratteristiche principali | Accuratezza |
|---|---|---|---|
| Sembly | Eccellente | ✓ Riconoscimento vocale tramite impronta ✓ ID in tempo reale ✓ Analisi dei relatori ✓ Profili personalizzati | 98% |
| Fireflies | Eccellente | ✓ Analisi del tempo di conversazione ✓ Monitoraggio del sentiment ✓ Approfondimenti sulle interruzioni | 95% |
| Gong | Eccellente | ✓ Tracciamento cliente vs rappresentante ✓ Rapporto di conversazione ✓ Rilevamento delle obiezioni | 96% |
| Otter.ai | Molto bene | ✓ Etichettatura facile ✓ Allenamento vocale ✓ Correzioni rapide ✓ Punti salienti | 90% |
Questi strumenti integrano l’identificazione del parlante nei loro flussi di lavoro principali, offrendo funzionalità come diarizzazione in tempo reale, analisi specifiche per oratore e profili vocali personalizzati. Che tu stia gestendo una grande riunione aziendale o un breve incontro con un piccolo team, scegliere lo strumento giusto può migliorare in modo significativo la qualità e l’usabilità dei tuoi riepiloghi delle riunioni.
⚠️ Sfide e Considerazioni
Sfide audio nel mondo reale
L'audio del mondo reale è disordinato. Accenti, parlato sovrapposto, rumore di fondo e altre caratteristiche vocali simili possono ridurre l'accuratezza. La segmentazione è più complessa quando le registrazioni sono brevi e di scarsa qualità, e l'addestramento supervisionato è limitato dalla privacy o dalla mancanza di dati etichettati.
✅ Cosa Aiuta la Precisione
- • Audio di alta qualità - Buoni microfoni, ambienti silenziosi
- • Voci distinte - Generi diversi, accenti, stili di parlato diversi
- • Sovrapposizione minima - Chiare turnazioni nei dialoghi
- • Relatori coerenti - Stessi partecipanti per tutta la durata
- • Registrazioni più lunghe - Più dati vocali per l'analisi dei modelli
- • Dataset di addestramento diversificati - Maggiore robustezza del modello
❌ Cosa Danneggia la Precisione
- • Scarsa qualità audio - Rumore di fondo, eco, distorsione
- • Tratti vocali simili - Stesso genere, età, schemi di parola
- • Interruzioni frequenti - Più persone che parlano contemporaneamente
- • Segmenti di parlato brevi - Dati vocali insufficienti per ogni speaker
- • Troppi interlocutori - più di 10 partecipanti creano complessità
- • Vincoli di privacy - Dati di addestramento etichettati limitati
💡 Best practice per i team
Per risolvere questi problemi, i team dovrebbero concentrarsi sull’ottenere audio di alta qualità, utilizzare una varietà di dataset di addestramento e impiegare una pre-elaborazione robusta al rumore. Una valutazione trasparente dei modelli e cicli di revisione umana contribuiscono inoltre a mantenere fiducia e accuratezza.
Analisi e approfondimenti sui relatori
Analisi del tempo di conversazione
😊 Sentimento per oratore
🔄 Modelli di Interazione
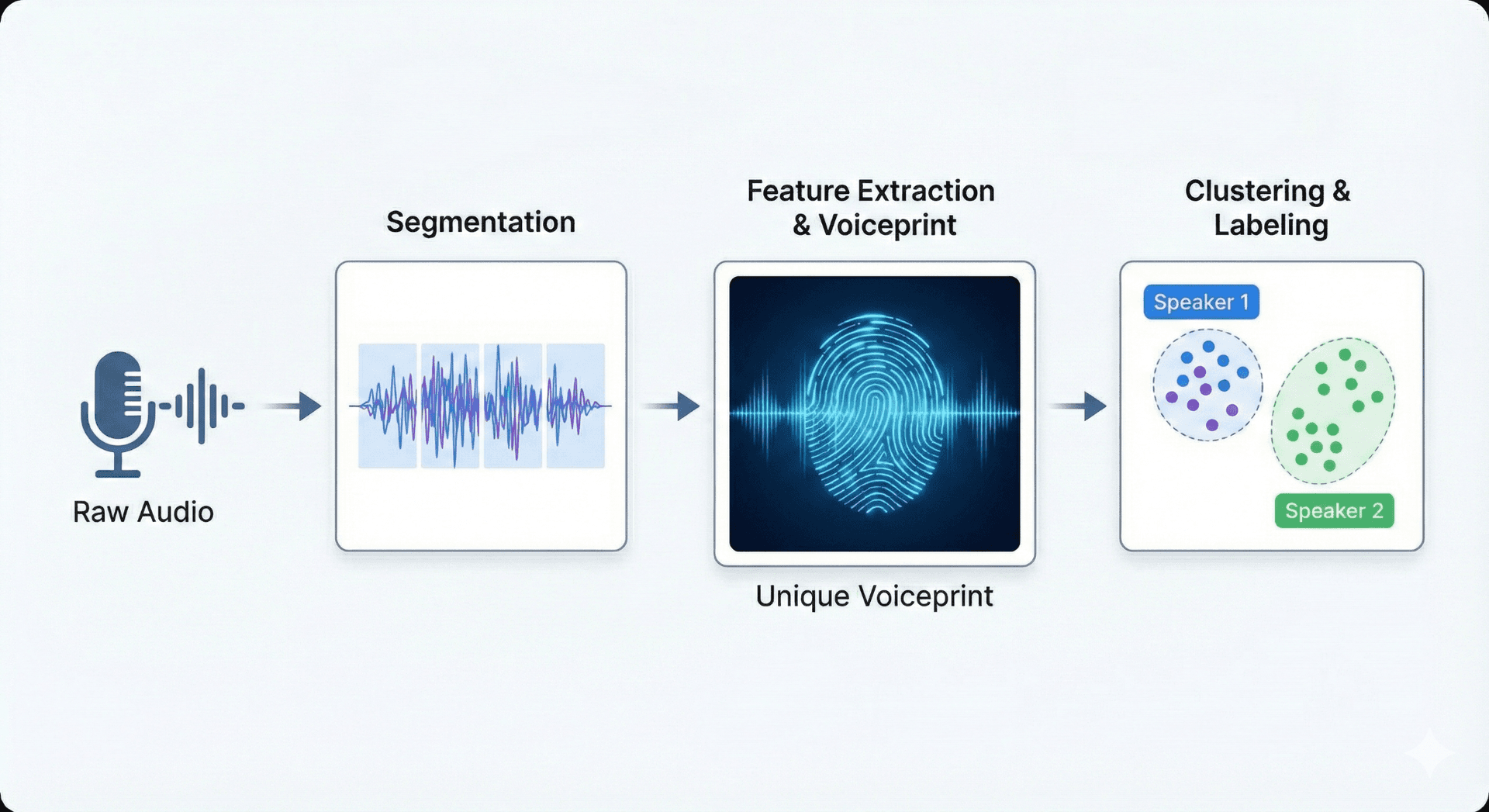
🔬 Panoramica della Tecnologia di Identificazione dei Parlanti
L'identificazione del parlante utilizza il machine learning, il pattern matching e l'estrazione di caratteristiche acustiche. I sistemi convertono prima l'audio in caratteristiche (intonazione, timbro, pattern spettrali) che catturano sia i tratti vocali fisiologici sia quelli comportamentali. Queste caratteristiche alimentano modelli, spesso reti neurali profonde o classificatori probabilistici, che imparano a separare ed etichettare i parlanti all'interno di una registrazione.
Diarizzazione dei parlanti
Segmentare l'audio in base ai turni di parola: determinare quando ogni persona inizia e smette di parlare.
- • Rilevamento dell'attività vocale
- • Rilevamento dei punti di cambio di parlante
- • Segmentazione audio per parlante
- • Creazione della timeline
Riconoscimento del parlante
Corrispondenza dei segmenti vocali con identità note e assegnazione delle etichette dei parlanti.
- • Corrispondenza dell'impronta vocale
- • Creazione del profilo dell’oratore
- • Verifica dell'identità
- • Assegnazione etichette
🚀 Futuro dell'Identificazione dei Parlanti
Aspettati che l’identificazione del parlante funzioni meglio insieme ad altre funzionalità di intelligenza artificiale, come il riepilogo sensibile al contesto che tiene conto dei ruoli dei relatori, la categorizzazione basata sulle emozioni e i sottotitoli in tempo reale che indicano chi sta parlando durante le chiamate dal vivo.
IA contestuale
Riepiloghi che comprendono i ruoli dei relatori e le relazioni
Rilevamento delle emozioni
Analisi del sentiment in tempo reale collegata a specifici interlocutori
Diversità Migliore
Precisione migliorata tra accenti e stili di parlato
Un apprendimento auto-supervisionato migliore e dataset vocali più grandi e vari renderanno più semplice comprendere accenti e contesti diversi. Questi cambiamenti, insieme a tecniche che preservano la privacy, renderanno gli strumenti per riunioni consapevoli del parlante sia più utili sia più rispettosi dei dati degli utenti.
🎯 Conclusione
L'identificazione del parlante trasforma l'audio non organizzato in informazioni utili che possono essere ricondotte alla persona che le ha pronunciate. Questo rende le riunioni più produttive e aiuta le persone a portare a termine i propri impegni. Gli strumenti di riepilogo basati sull'IA possono fornire trascrizioni più chiare, riepiloghi specifici per ciascun oratore e registri ricercabili sfruttando un'elaborazione audio avanzata, il machine learning e una gestione accurata dei dati.
🚀 Pronto per l’azione?
Scopri le funzionalità con riconoscimento dei relatori per vedere come possono aiutarti a gestire le tue riunioni in modo più fluido.